Self-evolving agent
I wanted something fundamentally different: an agent system that extends itself.
Most people using AI agents are doing prompt-in, text-out. Maybe they wired up a few API calls with LangChain. That's fine. But I wanted something fundamentally different: an agent system that extends itself. One that encounters a problem it can't solve, writes the tool it needs, tests it, deploys it, and integrates it — without asking me.
Here's how I built it, what went wrong, and why I think this pattern is the future of personal infrastructure.
The problem with static toolchains
Every agent framework gives you the same pitch: define your tools, write your system prompt, connect your LLM. But real workflows aren't static. Last Tuesday my agent needed to check DNS propagation status. It didn't have a tool for that. In a normal setup, I'd stop everything, write a function, register it, redeploy. That's exactly the friction that kills agent adoption.
What if the agent just... handled it?
Architecture overview
The system has four layers. Here's how a task flows through the system — from intake to execution, including the self-forging loop:
D --> F{Trust level check}
F -->|Trusted / Standard| G[Execute in sandbox]
F -->|Probationary| H[Execute + require confirmation]
E --> I[Reverse-engineer API spec]
I --> J[Generate MCP server code]
J --> K[Sandbox test - 3 stages]
K -->|Pass| L[Register in tool registry]
K -->|Fail| M[Self-repair loop]
M -->|Max 3 retries| J
L --> D
G --> N{Success?}
H --> N
N -->|Yes| O[Return result + update reliability score]
N -->|No| P{Retries < 3?}
P -->|Yes| Q[Diagnose failure]
Q --> R{Fixable via tool patch?}
R -->|Yes| E
R -->|No| S[Escalate to human]
P -->|No| S
O --> T[(Audit log)]
S --> T
style E fill:#1a1a2e,stroke:#e94560,stroke-width:2px
style L fill:#1a1a2e,stroke:#0f3460,stroke-width:2px
style G fill:#1a1a2e,stroke:#16213e,stroke-width:2px
The orchestrator is a LangGraph state machine. Nothing fancy — it handles task decomposition and routes to available tools. The interesting part is what happens when it can't route.
The tool forge
When the orchestrator encounters a task and no registered tool matches, it enters the forge loop:
class ToolForge:
async def forge(self, task_description: str, context: dict) -> Tool:
# Step 1: Semantic search for near-matches
candidates = self.registry.search(task_description, threshold=0.7)
if candidates:
return await self._adapt_existing(candidates[0], task_description)
# Step 2: Identify what API/service is needed
api_spec = await self._reverse_engineer_api(task_description, context)
# Step 3: Generate the tool code
tool_code = await self._generate_tool(api_spec, task_description)
# Step 4: Sandbox test
test_results = await self._test_in_sandbox(tool_code, api_spec)
if not test_results.passed:
# Self-repair loop (max 3 attempts)
tool_code = await self._repair(tool_code, test_results.errors)
# Step 5: Package as MCP server and register
tool = await self._package_and_register(tool_code, api_spec)
return tool
The key insight: the forge doesn't just generate functions. It generates entire MCP (Model Context Protocol) servers. Each new tool is a self-contained process with its own dependencies, its own Docker container, and its own stdio transport. The orchestrator discovers and connects to them exactly like any other MCP server.
API reverse-engineering
This is where it gets interesting. When the forge needs to create a tool for, say, Hetzner DNS management, it follows this pipeline:
-
Documentation retrieval — the agent searches for official API docs, OpenAPI specs, or SDK references. It prioritizes machine-readable formats (OpenAPI/Swagger JSON) over prose documentation.
-
Schema extraction — from the docs, it extracts endpoint URLs, auth patterns, request/response schemas, and error codes. This becomes a structured
APISpecobject. -
Auth pattern detection — it identifies whether the API uses bearer tokens, API keys in headers, OAuth2, or something else. It generates the auth boilerplate accordingly.
-
Code generation with constraints — the LLM generates a TypeScript MCP server (I standardized on TypeScript for the tool runtime) with these hard rules:
- All HTTP calls go through a rate-limited client
- All responses are validated against the extracted schema
- Errors are structured, never swallowed
- No secrets in code — everything reads from env vars
Here's what a forge-generated MCP server for Hetzner DNS looked like (cleaned up slightly):
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const server = new McpServer({
name: "hetzner-dns",
version: "0.1.0",
});
const API_BASE = "https://dns.hetzner.com/api/v1";
const apiKey = process.env.HETZNER_DNS_API_KEY;
server.tool(
"list-zones",
"List all DNS zones in the Hetzner account",
{},
async () => {
const res = await fetch(`${API_BASE}/zones`, {
headers: { "Auth-API-Token": apiKey },
});
if (!res.ok) throw new Error(`Hetzner API error: ${res.status}`);
const data = await res.json();
return {
content: [{ type: "text", text: JSON.stringify(data.zones, null, 2) }],
};
}
);
server.tool(
"create-record",
"Create a DNS record",
{
zoneId: z.string(),
type: z.enum(["A", "AAAA", "CNAME", "MX", "TXT", "SRV", "NS"]),
name: z.string(),
value: z.string(),
ttl: z.number().optional().default(3600),
},
async ({ zoneId, type, name, value, ttl }) => {
const res = await fetch(`${API_BASE}/records`, {
method: "POST",
headers: {
"Auth-API-Token": apiKey,
"Content-Type": "application/json",
},
body: JSON.stringify({ zone_id: zoneId, type, name, value, ttl }),
});
if (!res.ok) {
const err = await res.json();
throw new Error(`Failed to create record: ${JSON.stringify(err)}`);
}
return {
content: [{ type: "text", text: `Record created: ${name}.${type}` }],
};
}
);
const transport = new StdioServerTransport();
await server.connect(transport);
The agent generated this, tested it against the Hetzner API with a dry-run zone, and registered it. Elapsed time: about 90 seconds.
The sandbox testing pipeline
Every forged tool goes through a three-stage test before it touches the registry:
Stage 1: Static analysis. The generated code is parsed and checked for obvious issues — syntax errors, missing imports, unsafe patterns (eval, exec, unchecked shell commands). This catches roughly 40% of first-attempt failures.
Stage 2: Mock execution. The tool runs inside a Docker container with network access restricted to a mock server. The forge generates synthetic API responses based on the extracted schema and verifies the tool handles them correctly — including error responses, rate limit headers, and malformed payloads.
Stage 3: Live smoke test. If the API supports it, a single read-only request is made against the real endpoint. For the DNS example, it listed zones (a safe, idempotent operation). For APIs without safe read endpoints, this stage is skipped.
class SandboxTester:
async def test(self, tool_code: str, api_spec: APISpec) -> TestResult:
container = await self._spawn_container(
memory_limit="128m",
cpu_limit=0.5,
network="mock-only", # Stage 2
timeout=30,
)
# Generate test cases from the API spec
test_cases = self._generate_test_cases(api_spec)
results = []
for case in test_cases:
result = await container.execute(tool_code, case.input)
results.append(self._validate(result, case.expected))
# Stage 3: single live probe if safe endpoint exists
if api_spec.has_safe_read_endpoint:
live_result = await self._live_probe(tool_code, api_spec)
results.append(live_result)
return TestResult(
passed=all(r.ok for r in results),
errors=[r.error for r in results if not r.ok],
coverage=len([r for r in results if r.ok]) / len(results),
)
The trust and reliability system
Not all forged tools are equal. Each tool in the registry has a reliability score that evolves over time:
{
"tool_id": "hetzner-dns",
"created": "2025-04-12T09:14:22Z",
"created_by": "forge",
"reliability_score": 0.94,
"total_invocations": 47,
"successful_invocations": 44,
"avg_latency_ms": 340,
"last_failure": "2025-04-28T14:02:11Z",
"last_failure_reason": "API rate limit exceeded",
"trust_level": "standard",
"permissions": ["network:dns.hetzner.com", "env:HETZNER_DNS_API_KEY"]
}
Trust levels work like a promotion ladder:
- Probationary (first 10 invocations) — all results are logged and reviewed. The orchestrator asks for confirmation before using the tool in destructive operations.
- Standard (10+ successful invocations, >80% reliability) — the tool is used without confirmation for non-destructive operations. Destructive operations still require approval.
- Trusted (50+ invocations, >95% reliability) — full autonomy. The orchestrator uses it like a built-in tool.
- Degraded (reliability drops below 70%) — the tool is quarantined. The forge attempts a repair cycle. If repair fails, the tool is archived and a replacement is forged from scratch.
Self-repair in practice
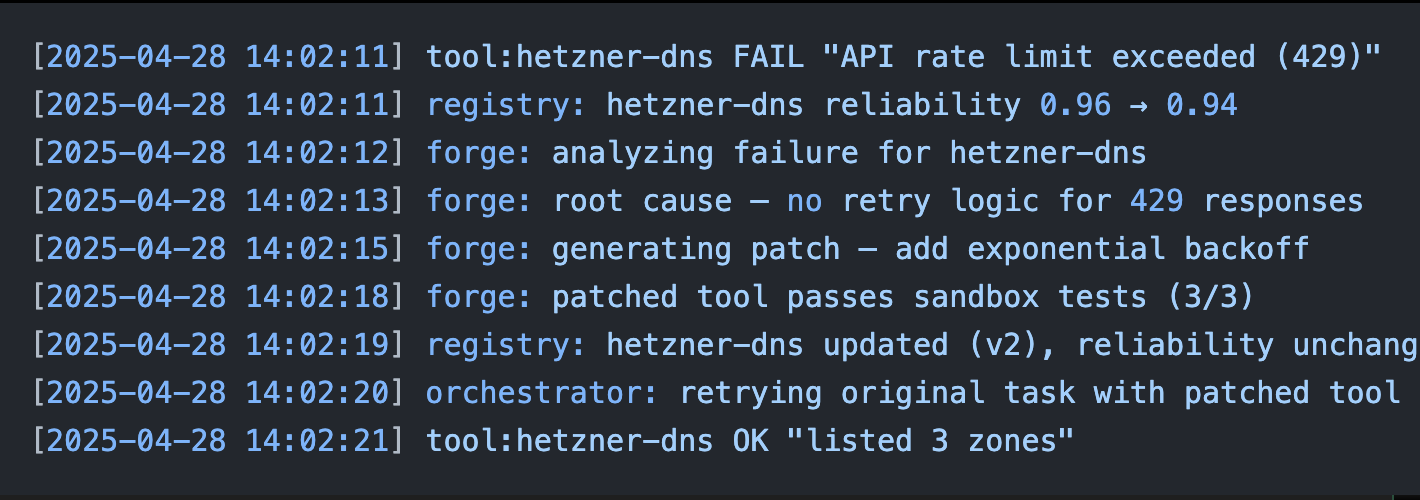
The most satisfying part of this system is watching it fix itself. Here's a real sequence from my logs:
[2025-04-28 14:02:11] tool:hetzner-dns FAIL "API rate limit exceeded (429)"
[2025-04-28 14:02:11] registry: hetzner-dns reliability 0.96 → 0.94
[2025-04-28 14:02:12] forge: analyzing failure for hetzner-dns
[2025-04-28 14:02:13] forge: root cause — no retry logic for 429 responses
[2025-04-28 14:02:15] forge: generating patch — add exponential backoff
[2025-04-28 14:02:18] forge: patched tool passes sandbox tests (3/3)
[2025-04-28 14:02:19] registry: hetzner-dns updated (v2), reliability unchanged
[2025-04-28 14:02:20] orchestrator: retrying original task with patched tool
[2025-04-28 14:02:21] tool:hetzner-dns OK "listed 3 zones"
The agent hit a rate limit. It diagnosed the missing retry logic. It patched the tool. It re-tested. It re-ran the original task. Total time: 10 seconds. I was making coffee.
What it's generated so far
In three months of running, the forge has created 23 tools. Some highlights:
| Tool | What triggered it | Trust level |
|---|---|---|
hetzner-dns |
SSL cert renewal needed DNS validation | Trusted |
ghost-api |
Wanted to check blog post analytics | Trusted |
uptime-checker |
Needed to verify a deployment succeeded | Trusted |
ssl-expiry |
Calendar reminder about cert expiration | Standard |
github-release-notes |
Asked agent to summarize a dependency update | Standard |
docker-log-parser |
Debugging a container crash loop | Trusted |
currency-converter |
Invoicing task needed EUR→CHF rate | Standard |
whois-lookup |
Investigating a domain for a side project | Probationary |
Four tools were archived after failing to maintain reliability. Two were replaced by improved versions that the forge generated after encountering edge cases the originals couldn't handle.
The security model
Giving an agent the ability to write and execute code is a controlled explosion. Here's how I contain the blast radius:
Principle 1: No ambient authority. Every forged tool declares its permissions explicitly — which domains it can reach, which env vars it reads, which filesystem paths it accesses. The runtime enforces these declarations via Docker network policies and seccomp profiles.
Principle 2: Write ops require approval. The orchestrator classifies every tool invocation as read or write. Reads execute immediately. Writes go through a human-in-the-loop step — I get a push notification with the proposed action and approve or reject. The only exception: tools at "Trusted" level performing operations they've successfully completed 50+ times.
Principle 3: Audit everything. Every tool invocation is logged with full input/output, latency, the LLM reasoning that triggered it, and the task context. I can replay any decision chain. This isn't optional — it's the foundation of debugging an autonomous system.
Principle 4: Kill switch. A single API call freezes the entire system. All running tools are terminated. The orchestrator enters a read-only mode where it can answer questions about what it was doing but can't execute anything. I've used this exactly once, when a forged tool was hammering an API endpoint due to a retry loop bug (before the backoff fix described above).
The hard parts nobody talks about
Dependency management is a nightmare. Each MCP server runs in its own container, but they share the host's Docker daemon. When tool #14 needs node:20-alpine and tool #7 was built on node:18-alpine, you're now managing a fleet of base images. I ended up standardizing on a single base image and rebuilding all tools weekly.
LLM-generated code is fragile across model versions. When I upgraded from Claude 3.5 Sonnet to Claude Opus 4 for the forge's code generation, six tools broke because the new model had different opinions about TypeScript patterns. The forge re-generated them, but the transition wasn't smooth.
Semantic search for tool discovery has false positives. The orchestrator once selected a "weather-api" tool when the task mentioned "weather" metaphorically ("let's weather this outage"). I added a confirmation step for tools below 0.85 similarity score.
Cost adds up. The forge pipeline — documentation retrieval, schema extraction, code generation, testing — burns through roughly $0.40 in API calls per tool. That's cheap for tools you use daily, expensive for one-offs. I added a "forge budget" — the system won't create more than 3 tools per day without approval.
Why this matters for SMBs
I built this for myself, but the pattern scales down beautifully. A small business doesn't have engineering bandwidth to build custom integrations for every SaaS tool they use. An agent that can forge its own integrations on demand — connecting the accounting software to the project tracker to the CRM — eliminates the "we need a developer for that" blocker.
The total infrastructure cost for running this system: about €15/month on a Hetzner VPS. The LLM costs for the orchestrator average €30/month. The forge costs are negligible after the initial tool creation burst.
For €45/month, I have an agent system that extends itself, heals itself, and handles operational tasks I used to spend hours on.
What's next
I'm working on three extensions:
-
Tool sharing. A registry where forged tools can be published and discovered by other instances of the system. Think npm for agent tools, but the packages are written by agents.
-
Cross-tool composition. The forge currently creates standalone tools. I want it to compose existing tools into pipelines — "check DNS, then verify SSL, then test HTTP response" as a single operation.
-
Adversarial testing. A red-team agent that actively tries to break forged tools by feeding them malformed inputs, simulating API outages, and testing permission boundaries.
The endgame isn't an agent that follows instructions. It's an agent that grows its own capabilities. The forge is a proof of concept that this is possible today, with current models, on commodity hardware.
If you want to talk about this architecture or try building something similar, find me on GitHub or reach out on LinkedIn.