Auto-tailor CV with n8n
build an end-to-end CV adaptation pipeline that take a job description and your CV, and outputs a perfectly aligned version
There’s a strange paradox about job hunting in tech: we automate everything except the act of tailoring our own CVs.
So, one afternoon, I decided to fix that.
I built an n8n workflow that takes my personal CV and a job description and spits out a brand-new, perfectly tailored version of my CV in PDF format. It’s formatted, keyword-optimized, and ready to send. No manual rewriting, no copy-paste, no tedious wordsmithing.
This is the story (and the architecture) behind my little automation experiment — a pipeline where AI meets workflow orchestration.
workflow automation
Every job post is a data problem. A job description is essentially a list of features (skills, experiences, keywords) that an algorithm — or a recruiter — wants to see.
Your CV is the dataset you’re trying to map to those features.
So, instead of rewriting my CV each time, I thought:
“Why not let an AI model do the rewriting — and let n8n handle the wiring?”
That’s exactly what this project does.
I drop in my master CV and a job link, and the workflow does the rest: parse, compare, adapt, generate, and output a PDF.
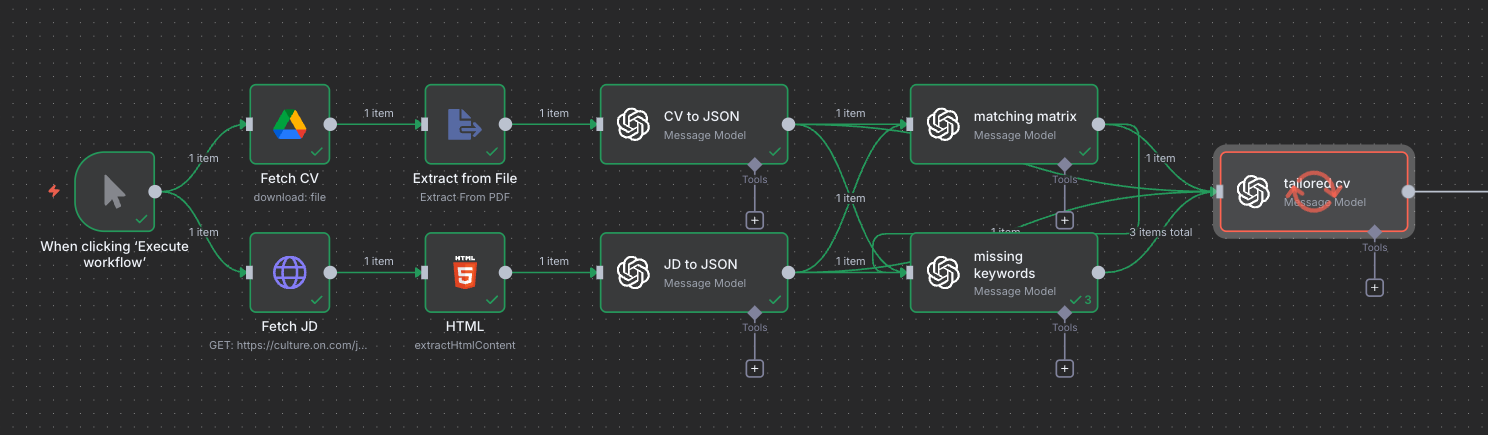
The architecture
Here’s what happens under the hood:
Manual Trigger
↓
HTTP Request → HTML Extract (job description)
↓
Read CV File → Extract Text
↓
OpenAI → Parse JD (structured JSON)
OpenAI → Parse CV (structured JSON)
↓
Merge (JD + CV)
↓
OpenAI → Generate tailored Markdown CV
↓
Markdown → HTML → PDF
↓
Upload to Google Drive
Each step is modular, so I can swap components (e.g., Claude instead of GPT-4, or Notion instead of Drive) without breaking the flow.
Parsing everything
Both the job description and my CV start as unstructured text — one scraped from the web, one extracted from PDF.
To make them comparable, I use two OpenAI nodes:
Parse CV to JSON
Prompt:
“Extract candidate name, location, contact info, education, roles, skills, and experience highlights.”Parse JD to JSON
Prompt:
“Extract role title, responsibilities, required skills, technologies, and seniority level from this job description.”These return structured JSON objects, e.g.:
{
"name": "Yan Niznik",
"location": "Zurich, Switzerland",
"roles": [
{
"title": "Principal Engineer",
"skills": ["Vue.js", "Nuxt3", "GraphQL", "Performance Optimization"]
}
]
}
and
{
"role_title": "Senior Frontend Engineer",
"skills_required": ["React", "TypeScript", "GraphQL"],
"responsibilities": ["Build scalable UI systems", "Lead cross-functional initiatives"]
}
Merging CV <> JD
Next comes the Merge node, which simply multiplexes the two JSONs into one combined object.
This combined payload is what feeds into the Tailored CV node — the real brains of the operation.
The AI step
The Tailored CV OpenAI node takes both datasets and generates a new, context-aware Markdown CV.
System prompt excerpt:
“You are a professional CV editor. Rewrite the candidate’s CV using the source information, keeping name, location, and personal details intact. Highlight relevant experiences and skills that match the job description. Use clear, ATS-friendly phrasing.”The result is a complete CV in Markdown — still my story, but adapted to the language and expectations of the specific role.
It often cuts irrelevant projects, reorders sections, and rephrases achievements to match the job’s tone.
Example snippet:
# Yan Niznik
Zurich, Switzerland • yan@yananas.com
## Professional Summary
Principal Engineer with 10+ years building large-scale e-commerce and performance-driven frontends. Experienced in Vue, Nuxt3, and GraphQL ecosystems. Passionate about system stability and web vitals optimization.
## Experience
**Principal Web Engineer**
*2021–Present*
- Led the migration from legacy SSR to Nuxt3 microfrontends.
- Improved LCP by 38% through backend-fed render optimization.
- Mentored team on Apollo Federation adoption.Markdown to PDF
At this stage, I had a great Markdown file — but I wanted a polished PDF.
n8n doesn’t have a native PDF renderer, so I used PDF Generator API, which turns HTML into clean, styled PDFs.
Before calling it, I convert the Markdown to HTML and inject a minimalist CSS block:
const md = $json.cv_markdown;
return {
json: {
html: `
<html>
<head>
<style>
body { font-family: "Helvetica", sans-serif; font-size: 12pt; line-height: 1.4; color: #222; }
h1 { font-size: 18pt; }
h2 { font-size: 14pt; margin-top: 20px; }
ul { padding-left: 20px; }
</style>
</head>
<body>${md}</body>
</html>`
}
};Then, the PDF Generator API node takes {{$json.html}} as input and returns a base64 PDF file, which is converted to binary and uploaded to Google Drive.
End result:
A beautifully formatted, job-tailored PDF CV titled Tailored-CV-SeniorFrontendEngineer.pdf.
n8n is the perfect glue
I could have scripted this in Node.js, but n8n makes the flow visual and modular:
- runs locally, no vendor lock-in.
- supports any API with minimal config.
- chain OpenAI, HTTP, and Drive nodes without writing code.
- every node shows its input/output, which is invaluable when debugging AI prompts.
The OpenAI nodes in n8n are especially elegant — they support structured JSON mode, system messages, and variable injection with $json interpolation.
It feels like coding with Lego bricks that just happen to call GPT-4.
Snippet: Base64 → Drive upload
The final step was saving the generated PDF automatically.
PDF Generator API returns the file as a base64 string, so I added a tiny Function Item node:
const base64 = $json.response;
const binaryData = Buffer.from(base64, 'base64');
item.binary = {
data: {
data: binaryData,
mimeType: 'application/pdf',
fileName: 'Tailored-CV.pdf',
},
};
return item;Then I connected it to Google Drive → Upload, with Binary property: data.
Done, I now have a new PDF in my Drive every time I trigger the workflow.
Results
The first test blew me away.
I fed a test-CV and a random “Dynamics 365 Solution Architect” posting from LinkedIn.
In less than a minute, I had a customized, professionally rewritten CV that:
- Preserved the personal info
- Emphasized relevant projects
- Cut unrelated items
- Looked clean and consistent in PDF format
It was better than what I would have written manually.

Future ideas
This workflow is just the beginning. A few next steps I’m exploring:
- Auto-email to recruiter: attach the tailored CV and send a custom cover letter via Gmail API.
- LinkedIn integration: detect new job postings, trigger the workflow automatically.
- Feedback loop: feed recruiter responses back into the model to improve tailoring.
- Notion history: log every generated CV for version tracking.
n8n makes all of that trivial — I’d just drop new nodes and connect them to the pipeline.
Takeaways
Building this reminded me why I love automation:
- AI is powerful, but orchestration is everything.
- n8n bridges APIs and creativity, it turns prompts into real-world systems.
- LLMs are best used when contextualized, by structured data, logic, and workflow states.
If you want to play with AI beyond the chatbox, wire it up.
Give it data, give it flow, give it context.
In my case, it gave me a better CV.
TL;DR:
I built a workflow that:
- Takes a CV and a job description.
- Parses both via OpenAI into structured JSON.
- Lets GPT-4 rewrite the CV for the job.
- Converts Markdown → HTML → PDF.
- Uploads it to Drive automatically.
It’s my personal AI recruiter, built in an afternoon with n8n.